CAP理论:Consistency,Availability,Partition tolerance

对于一个分布式数据系统,CAP三要素不可兼得,至多实现其二。要么AP,要么CP,不存在CAP。分布式系统往往要求必须满足P。

传统关系数据库选择CA,NoSQL更关注AP。
CAP Reloaded:
关系数据库ACID原则:Atomicity,Consistency,Isolation,Durability;更强调数据一致性
NoSQL系统BASE原则:Basically Available,Soft state,Eventual consistency;更强调数据可用性
幂等性(Idempotent):

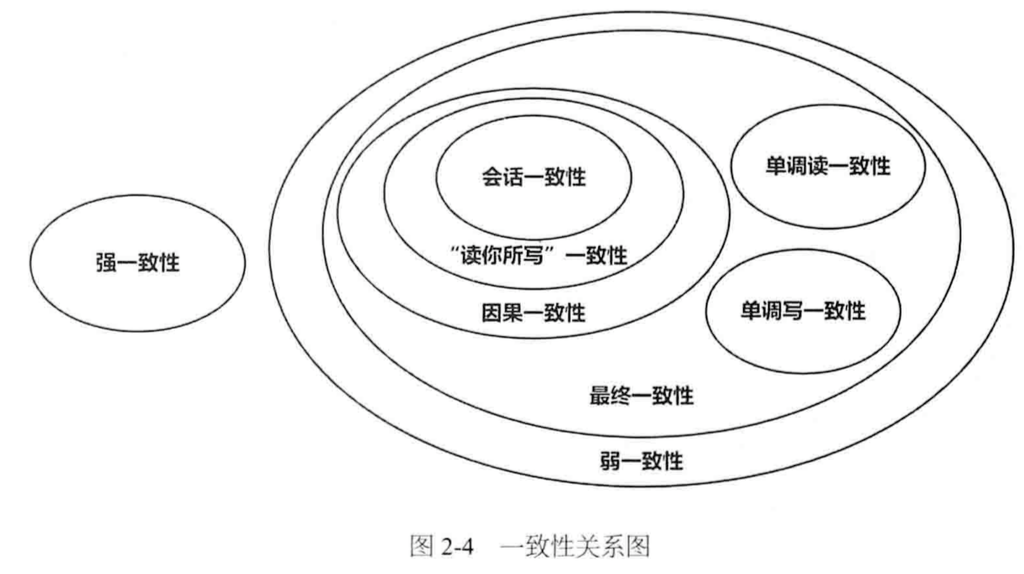
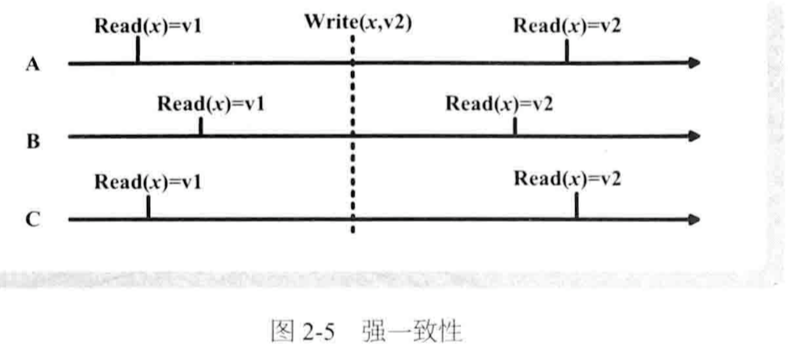
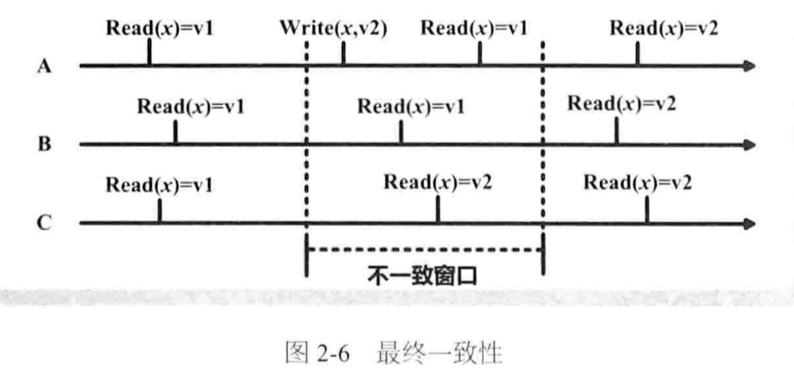
一致性模型分类:
副本更新策略:
延时和一致性做权衡
策略1-同时更新:
A 同一时刻的两个写请求,无法保证各副本操作顺序一致
B 通过某种一致性协议确定执行顺序
策略2-主从更新:
一个主副本(master replica),多个从副本(slave replica)。写主副本,主副本转发写给从副本,主副本决定写顺序。
A 同步方式:主副本等待所有从副本写完,视作操作完成。请求延时大
B 异步方式:主副本通知从副本写之前视作完成。应对主副本未通知前崩溃的情形:指定存储记录此次写操作(比如log文件)
1.读请求都转发给主副本:代价是高延时。eg:Chubby
2.所有副本可读:代价是弱一致。eg:PNUTS,Zookeeper
C 同异步混合:主副本同步写部分从副本,视作完成,异步写其他从副本
1.读的数据必须来自同步写的节点:强一致,高延迟
2.同1相反
策略3-任意节点更新:
A 同步通知:强一致,高延时
B 异步通知:弱一致,低延时
一致性协议:
两阶段提交(two-phrase commit,2PC)协议:
解决分布式事务问题:实现ACID中原子性(Atomicity)。eg:Raft一致性协议用其保证信息更新原子性。
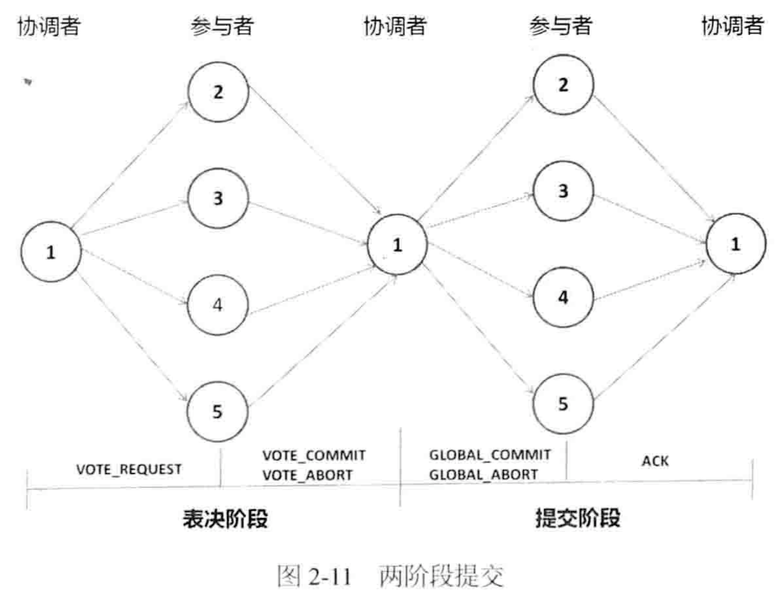
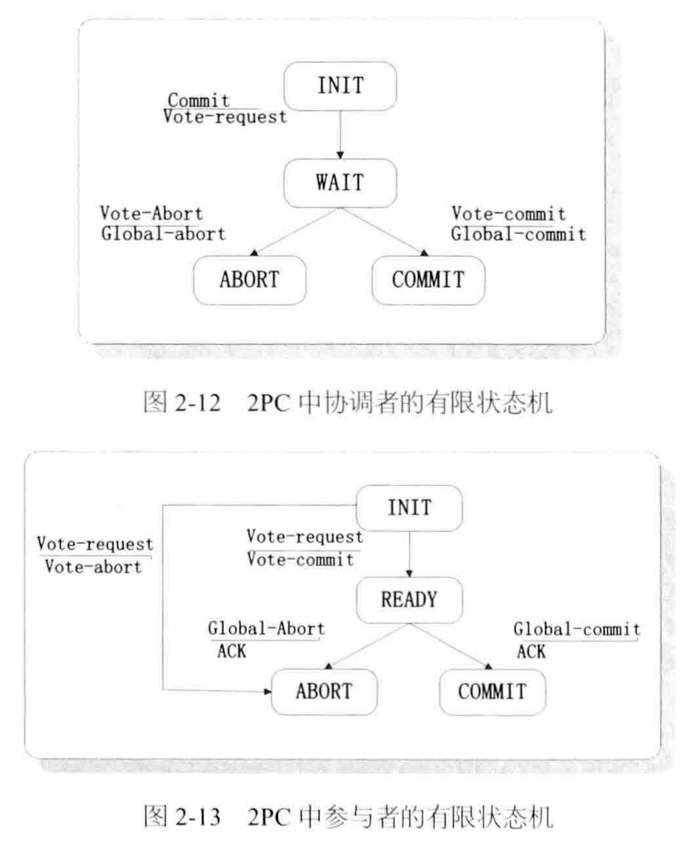
存在3个阻塞态:协调者的WAIT态,参与者的INIT态、READY态
解决阻塞问题:
1 超时判断:协调者WAIT态若超时发Global-abort,参与者INIT态超时发Vote-abort
2 参与者互询:参与者READY态超时不能abort事务,因为不确定协调者下发表决信息,所以需要互询。
参与者P问参与者Q:
if Q=COMMIT then P:=COMMIT
if Q=ABORT then P:=ABORT
if Q=INIT then P:=ABORT
if Q=READY then P问其他参与者;最坏情形是其他参与者也都出于READY态,即长时阻塞(还好较少发生)
解决长时阻塞:协调者和参与者将自身状态写入本地log,崩溃重启根据log恢复。
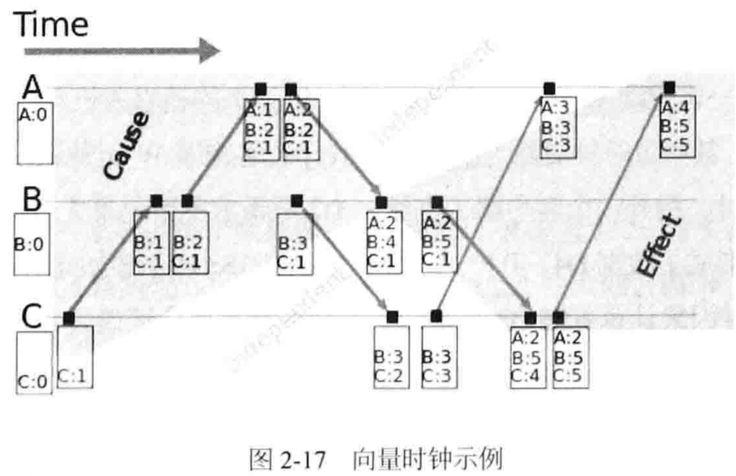
向量时钟(vector clock)协议:
将时间戳和事件绑定进而判定事件因果依赖关系。
规则:

判断因果关系:

例子:

Dynamo使用向量时钟管理数据版本。
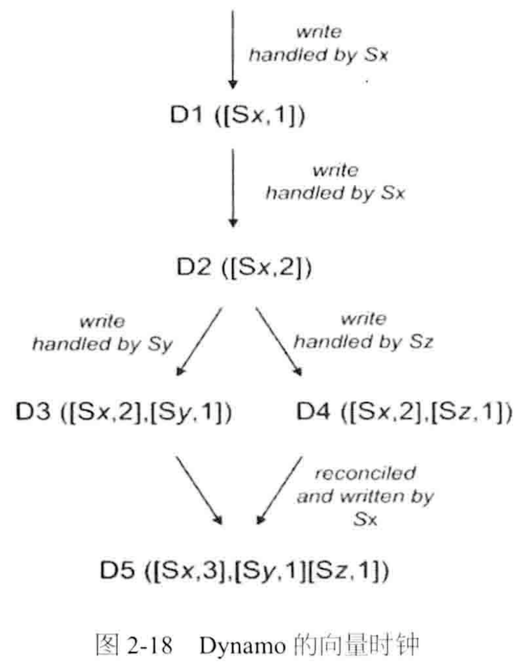
如有数据一致性冲突经向量时钟无法判定,则交给客户端(应用端)判定。
RWN协议:

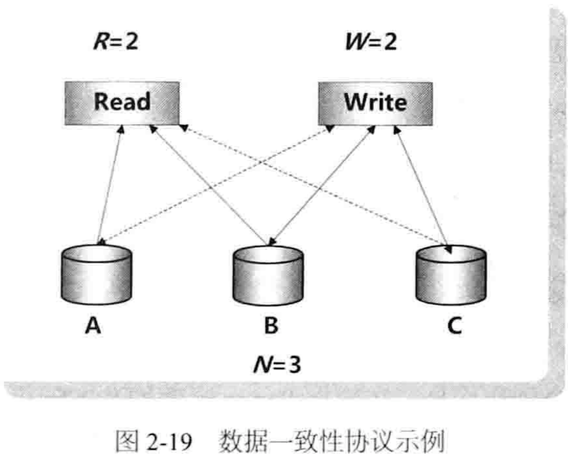
R或W越大延迟越高。
可根据实际情况配置R和W的数值。
必须结合向量时钟配合达到强一致性。
Paxos协议:
1. 副本状态机模型(replicated state machines)
典型实现:Log副本方式
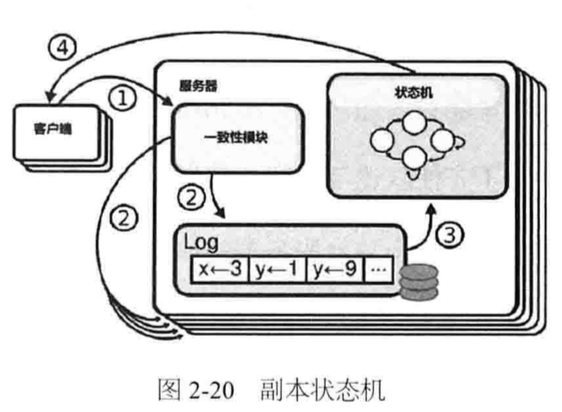
一致性协议作用是保证各个Log副本数据的一致性:一致性模块(consensus module)

2. Paxos基本概念




3. Paxos协议机制



学习者获取倡议:


Raft协议:
目标:可理解性,实现实际系统的确定性

基本概念


1. 领导者选举


2. Log复制

(注:项目即item)
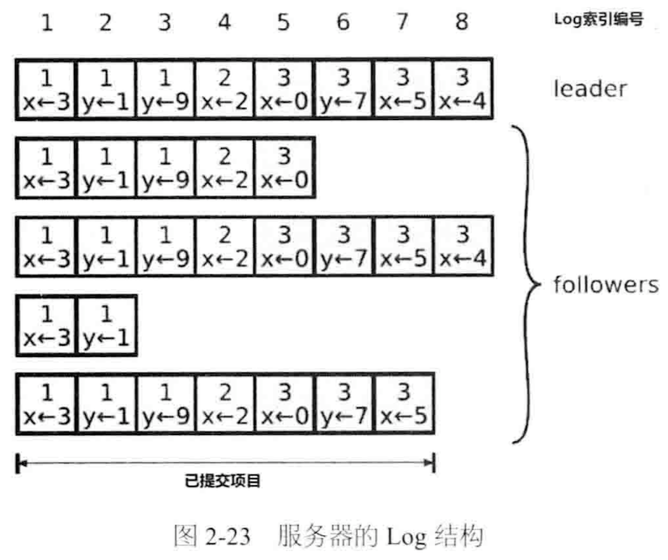

3. 安全性


| Zookeeper | Raft | Chubby | PNUTS | Dynamo | Cassandra | Riak | |
| 介绍 | Yahoo | Amazon,NoSQL | NoSQL | 模仿Dynamo | |||
| 操作 | idempotent | idempotent | |||||
| 副本更新 | master-slave read | master-slave async: read master | master-slave async: read all | master-slave sync+async | master-slave sync+async | master-slave sync+async | |
| exception: random | exception: random | exception: random | |||||
| 一致性协议 | vector clock+RWN |